

Introduction
It should not come to a surprise that the Chinese technology giants are — just as their western counterparts, rolling out their respective versions of cloud storage services such as Google Drive, Dropbox, or OneDrive.
They are approaching it like most of their offerings:
- Explore and learn from foreign competitors.
- To help out, the government will oftentimes approve these foreign companies to enter the Chinese market. Dropbox has quite some users in China, so does Gmail.
- The technology giants move a massive amount of manpower around to whip up a similar offer in a short amount of time.
- At this stage, do not be surprised that the government “coincidentally” blocks access to foreign competitors (Google and Dropbox again are good examples) [1].
- The Chinese technology giant meanwhile lures users with an offer they can’t refuse. (More about what this means in practice later.)
- When luck strikes, the giant is able to maintain a hugely successful service. Baidu (search), Taobao, Weixin and QQ for instance are such success-stories.
In other cases, however, some services also end up being kept-alive in some sort of zombie state. Tencent’s Qzone for instance is massively popular in terms of user base, but doesn’t get much love feature-wise. Baidu’s Baike was supposed to be a Wikipedia clone and has surpassed the latter in terms of articles (for the Chinese Wikipedia, that is), but is lacking in terms of interface and infrastructure, and less curated, with less useful or inaccurate articles as a result [2]. Although the Chinese Wikipedia is also sub-par. - In any case, after some time has passed, the “unrefusable” offer will end up being buried under more and more rules (identification, usage restrictions, etc.). Users begrudgingly accept this until something new comes along.
Of course, the above is a widely generalized, short cut version of the story, although the basic idea is valid.
That said, it is too easy to just regard overlooked services or an overload of rules to be caused by a lack of expertise or knowledge, as there is more going on. Sure, a social network not receiving much love will be down once in a while, and a game might be unable to connect to some server from time to time as well, but no real harm is done and in most cases a team is scrambled to get things running again. However, many of these things are done in a very ad-hoc, seemingly chaotic manner which looks confusing, daunting and maybe untrustworthy to outsiders. There are many things at play at the same time here:
- Tendency to copy. It is easy to describe this with the stereotypical “lack of creativity” one-liner, which is an oversimplification, although there is a clear presence of “they have it, we also better have it”-mindset going on.
- Labor is cheap. This allows companies to push a lot of manpower around.
- Things are being ran efficiently, but seemingly ad-hoc.
- Changes can come quickly and rapidly, as well as new rules and policies. Privacy concerns are also seen as a lesser… concern, and most users expect and know this.
- The scale is absolutely massive.
Now compare this to western players (keep in mind that I’m still mainly talking about technology companies):
- Tendency, desire and pressure to innovate.
- Labor is expensive. Going from innovative toy to wide-scale implementation costs a lot.
- Things are being ran efficiently, with attention to detail.
- Changes come slowly and a great amount of time is spent on user-guidance. Remember the last time Facebook changed a color or something and users where up in arms? Rules and regulations are researched ahead of time before launching (“lawyering up”). Privacy concerns are crucial, but failure is possible, leading to a big PR scandal, as users are very sensitive to this.
- The scale can be massive, but not immediately. Growth curves look a lot different.
I’m going off on a tangent now, but whenever talking about this, I always like to mention payment providers and retail platforms as a fitting illustrating example. There are companies such as Alibaba with their Taobao platform which are absolutely killing it in terms of online retail (again with a scale and a certain amount of “busy-ness” Amazon can hold a candle to). A vast amount of companies, banks, public service institutions and even restaurants have payment and other support systems in place which all work very well, also on smartphones (the primary computing platform in most of Asia). PIN codes are 6 digits, logins are verified with a text message or a QR code (those which were all the rage in western territories for a while and then mostly died out due to lack of adaption). Of course, users get hacked, scammed, or tricked all the time, but this is mainly caused by the massive scale (more targets) and again is easy to mistake for a lack of efficiency (also again since everything kind of seems to be set up in a chaotic, intertwined and rather ad-hoc manner). Sure, you can expect a fair share of self-signed SSL certificates or the government snooping in, but these are mainly caused by a more-rules-is-always-better culture and the lack of concern for privacy. And again, most users know this. For more great stories in this context, look for instance at the way how Bitcoin has been adopted (and pushed out) in China, complete with mining factories, really. In fact, Tencent also tried to release some sort of digital currency (though, centralized, of course) many years ago, called “Q Coin” which was also deserted later on, under government pressure.
Another great related recent article is this one on the topic of Chinese Mobile App UI/UX trends, which also provides great insights in the mobile appsphere mentality.
Cloud Storage
But I digress… this post was going to be a simple one, about cloud storage services. As stated before, Chinese technology firms have begun offering cloud storage services:
- Baidu Disk - or: Baidu Yun (云, cloud) or Pan (盘, disk [3]): offers 2TB (that is terabytes!) of data for free when you install the mobile app.
- Tencent Weiyun: offers 10TB of data for free when you install the mobile app.
- 360.cn’s Yunpan: offers 10TB of data when installing the Windows client and an additional 20TB when installing a mobile client.
Just to compare: Dropbox gives you a meagre 2GB for free (although it is pretty easy to work this up to around 5-10GB), Google Drive gives 15GB, OneDrive also 15GB and Box gives 10GB. It is possible to find some other providers giving up to 100GB away, but no massive 1TB+ offerings as with the Chinese.
So where’s the catch? There must be a catch, right? Let’s take a look at some of the common patterns occurring across the aforementioned three services…
Pattern 1: Chinese Only, More or Less
When you try to go to 360 Yun‘s or Weiyun‘s homepages, this is what you’ll get:

With no English in sight — or even the option to switch language — it is clear that they are targeted to a Chinese audience only, at least for now. Honorable mention: Weiyun does have an English version of their web app over at http://www.weiyun.com/disk/index-en.html, but it doesn’t get as much love as the Chinese one, and you’ll still see Chinese error messages popping up.
Luckily, at least for the web apps, Chrome’s translation option is able to help out a great deal.
Pattern 2: Copy Galore, with Some Differences
When you stack the logos of all three services above each other, a similarity emerges:

When you compare the interfaces, things look mostly the same as well, with Baidu standing out thanks to a black header bar and an uglier font.

Similar as these apps might seem, they do differ in terms of functionality… here are some notable aspects:
- Possibilities to share content differs among all services. Sometimes you get a link which ends up in a ZIP download, sometimes you can add it to your own drive, sometimes you get a barcode, and so on.
- Baidu allows you to upload a torrent file which will be downloaded. They do some rudimentary checks for illegal content, however.
- All three implement support for pictures, video, and music which can be viewed right from the app. They also support viewing Office documents and PDF’s. The reliability of rendering however differs from service to service.
- Here’s something interesting to try: see how easy you can upload multiple files at once through the web app. Weiyun does allow to drag and drop files, but not folders. The English version does not support drag and drop at all. 360 allows drag and drop of files, but not folders. You can upload folders however through a separate drop down and selecting the folder, but not if the folder contains sub folders. Baidu also does not support drag and drop. The reason for this? Folder dragging is only supported by Webkit (Chrome) at the moment, but it still seems strange that no more middleware libraries such as filedropjs are used which already take this into account.
Pattern 3: Arbitrary Limits
All apps examined here absolutely love imposing arbitrary limits. Want to upload a selection of n+ files at once? Sorry, only so much at a time, please. Want to create this deep of a folder tree? Nope. Want to name your file like this? Nope. Want to upload a file larger than 360MB? Nope (how cute).
For many of these limits, it’s not exactly clear what is driving this. Perhaps imposing limits allows for easier monetization later on? Perhaps this is a way to drive people to use the add-ons, which brings us to…
Pattern 4: A Web App, a Plugin, a Client, a Mobile App…
Whereas both Dropbox and Google follow the strategy to put most in an accessible web app and offer a small sync client to install on your computer, the Chinese counterparts go all out and offer a wealth of apps — a pattern which is very typical. Meaning that you’ll end up with: the web app, the plugin to install in the web browser and allows extra features (many of which could be offered by using latest-and-greatest Javascript developments such as websockets), a client, a syncing tool, and a mobile app or two.
This means that whenever you want to do something meaningful through the web app, you’ll be asked to install the appropriate plugin:
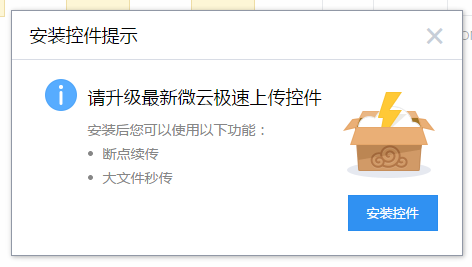
Leaving you with:
Although I have no evidence suggesting that these plugins are up to no good, I’d be a bit wary of just installing any client or plugin on my machine… especially when considering…
Pattern 5: What Privacy?
This is a fun one. First of all, let’s take a look at some of the permission screens you’ll be greeted when trying to install these mobile apps:
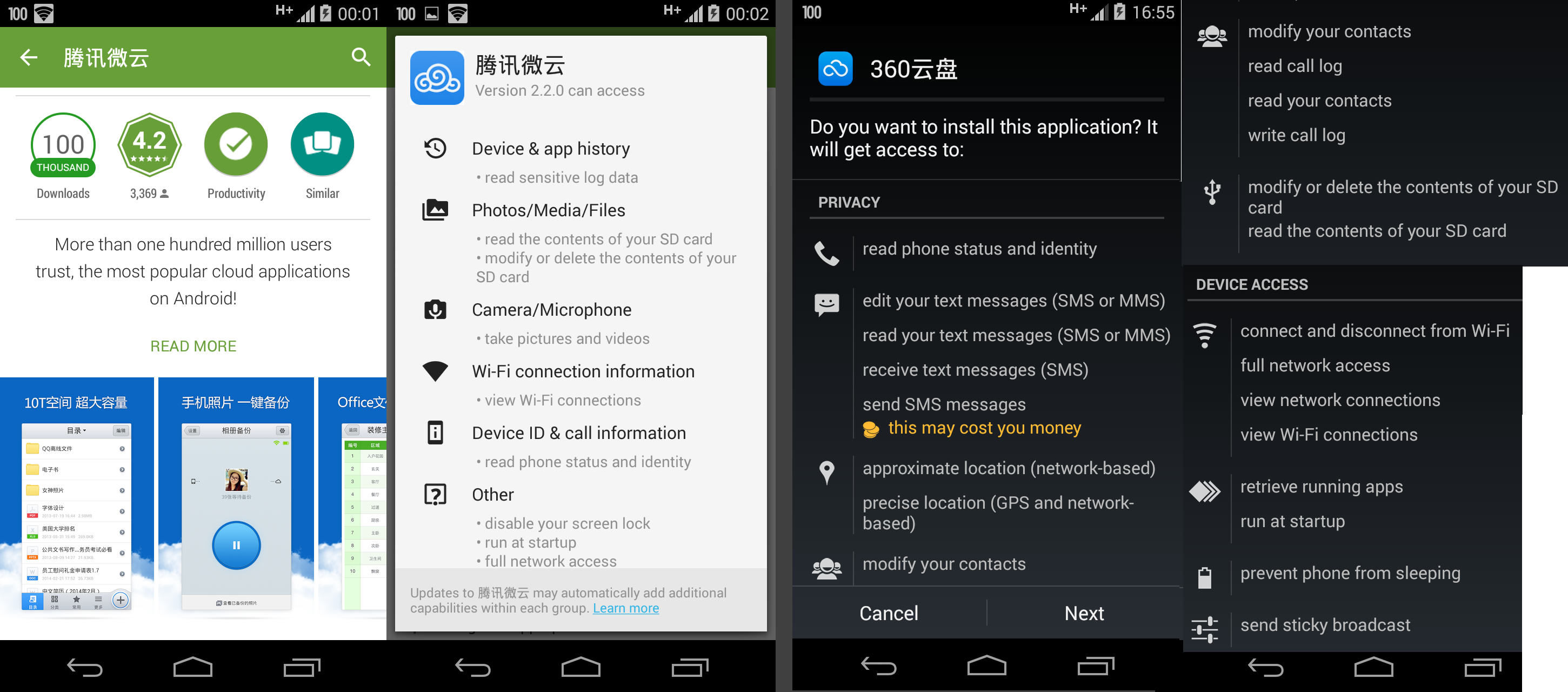
Boy this looks scary! Change my wifi connections? Send messages? What is a sticky broadcast? Why do you want to change my contacts? It might be the case that this is a case of sloppy programming, but especially 360’s app seems to go completely overboard.
In addition, upon using these services, you’ll notice that most of them will perform some sort of scanning of your files before uploading them, and that — in some cases — upload goes lightning fast! What could be the reason? Apparently there is some sort of hashing going on which compares your file’s hash to other files which have been uploaded to the service. When a match is found, the cloud service can make the file appear in your drive without actually having to upload the file. I’ve tested this extensively with Weiyun (more on this below), and the matching works even when you delete the file afterwards, and can allow you to add files even if you do not have the actual file. Is this an issue? Not in itself, but just be aware of the fact that no encryption is happening anywhere (Dropbox used to apply similar techniques but then toned it down due to user complaints). So make sure to encrypt your files yourself before uploading them.
Finally, I love the following screen which is just one tap away in 360’s app:

This shows an overview of popular photo albums… I have no idea why this belongs in a cloud storage app, but it seems to suggest that you can pretty easily share your uploaded albums with the world… Hmm.
Pattern 6: “Sure”, It’s Reliable…
I mentioned before that in case of things going awry, it doesn’t take long for a fix to be implemented. This is true, but doesn’t prevent these services to break… quite a lot… for reasons related to the arbitrary limitations as discussed before, or just other reasons.
For instance, I’ve been notified with the following screen during the past two days when trying to upload MP3 files to Weiyun:

(I’m using a third party translation here, which is why the client shows in English.)
Over on the web app, we see:

Which basically translates to: under maintenance. When will this be fixed? Who knows — although it should be rather soon. What is the root cause? Who knows.
Pattern 7: An App Among Apps
Finally, the last item worth mentioning — as was also said before — is the fact that these offerings are only a small part of the total amount of apps, tools and services Baidu, Tencent, and 360 offer. For example, a look at 360.cn shows this staggering amount of… stuff:

A Little Reverse Engineering
To close off this post, I’m going to present a little reverse engineering I did to make a hand-rolled Weiyun API. Forget about these services offering an official API, so it’s back to forging CURL requests and screen scraping for anyone who wishes to access their files in a programmatic manner.
I’ve chosen Weiyun, because they have the best English support, are relatively trustworthy (they have a long running “international” version of their QQ client), and offer a large amount of storage. I prefer not to use 360 as I know from experience that many of their apps are less than trustworthy (case in point: you’ll find 360 crapware running on about 90% of Windows XP installations when in China, their “browser” is also notorious for just being an IE reskin with self-signed certificate warning disabled, with makes it great for enabling man-in-the-middle attacks as the Golden Shield is want to do).
I’ll be using the English version of the Weiyun web app over at http://www.weiyun.com/disk/index-en.html as a base here. After logging in and fiddling around, we immediately see a bunch of requests popping up in Chrome:
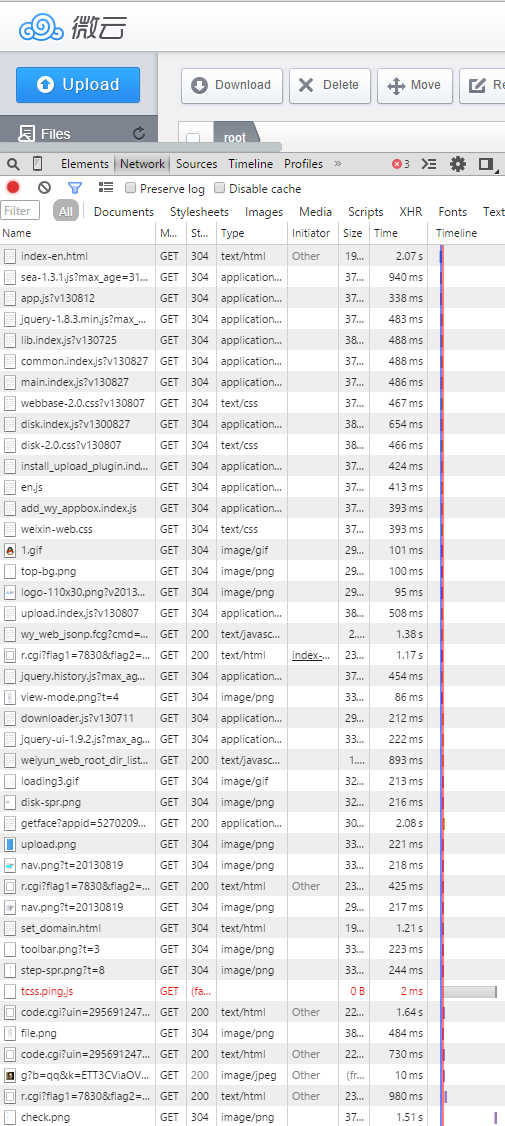
After a while, a pattern starts to emerge. It seems that every request calls an endpoint at http://web.cgi.weiyun.com, also followed by requests to code.cgi and r.cgi, which include a lot of flags but do not provide a response, so they seem to be tracking/analytics related and can perhaps be ignored for now.
Our requests of interest, however, mostly seem to be performed over GET and compose an url like so:
http://web.cgi.weiyun.com/: hostname.weiyun_web_root_dir_list_cgi.fcg: name of the endpoint.?cmd=root_dir_list: name of command. It is strange that this is included, as the names of the endpoints already differ and indicate which action should be executed.&g_tk=984964540: some kind of token which is sent along with every request. This number does not change, however, so we can just hard code it.&callback=get_RB7C197F8_8465_49DB_AEC7_273C1DC50470: name of the callback function which the JSONP formatted response will call. This is generated randomly client-side, so we can emulate this behavior.&data=%7B%22req_header%22%3A%7B%22cmd%22%3A%22root_dir_list%22%2C%22main_v%22%3A11%2C%22proto_ver%22%3A10006%2C%22sub_v%22%3A1%2C%22encrypt%22%3A0%2C%22msg_seq%22%3A1%2C%22source%22%3A30234%2C%22appid%22%3A30234%2C%22client_ip%22%3A%22127.0.0.1%22%2C%22token%22%3A%22b8df84ae2f33849126bd9e7888c97b5b%22%7D%2C%22req_body%22%3A%7B%7D%7D: JSON formatted request payload.&_=1420213473426: some kind of random token or timestamp. Probably to avoid caching issues.
Taking a closer look at the data payload, it looks something like this:
{"req_header":: the request header.{"cmd":"root_dir_list",: the command value repeated again. Somewhat redundant."main_v":11,: a version number."proto_ver":10006,: protocol version number."sub_v":1,: sub version number."encrypt":0,: encryption flag. I’ve not seen this used or enabled anywhere."msg_seq":1,: message sequence? Funnily enough, this stays at one and is not incremented."source":30234,: another id."appid":30234,: same as above, id indicating the application?"client_ip":"127.0.0.1",: hardcoded to be127.0.0.1, perhaps the developers had plans to change or use this later on."token":"b8df84ae2f33849126bd9e7888c97b5b"},: a token which seems to be used to prevent CSRF attacks, but also stays the same for every request, and is thus easy to hardcode.
"req_body":{}}: the request body, empty here but will be filled up with additional arguments.
Last, we also need to take a look at the cookies send with every request:
pgv_info: some kind of session indicator? Values look likessid=s9869263628and do not tend to change after a session timeout.pgv_pvid: same. Values look like4842874884pt2gguin: the letter “o” followed by your QQ number.ptcz: also a session identifier which does not tend to change after a session timeout.ptisp: set to the valueosptui_loginuin: your e-mail address.skey: a session key which does change after a session timeout, starts with “@”.uin: same aspt2gguinabove.verifysession: a remainder of the login process, but not required in the app itself.
With this under our belt, we’re ready to start of with some code. First, we set up our imports and values we need to retrieve from a started session:
import requests
import uuid
import json
import time
import os
import hashlib
import sys
import struct
import binascii
# Change the values below:
SKEY = '@changeme'
UIN = '29changeme'
PTCZ = '97changeme'
PGV_INFO = 'ssid=s9changeme'
PGV_PVID = 'changeme'
EMAIL = 'changeme@changeme.changeme'
Next, some general purpose functions:
current_milli_time = lambda: int(round(time.time() * 1000))
file_size = lambda x: os.stat(x).st_size
get_ordered_tuple = lambda x,y: next(a[1] for a in x if a[0] == y)
md5 = lambda x: hashlib.md5(open(x, 'rb').read()).hexdigest()
sha1 = lambda x: hashlib.sha1(open(x, 'rb').read()).hexdigest()
jsonprint = lambda x: json.dumps(x, sort_keys=True, indent=2, separators=(',', ': '))
And some additional constants we’ll be using throughout:
TOKEN = 'changeme'
GTK = 'changeme'
HEADERS = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36' \
' (KHTML, like Gecko) Chrome/37.0.2062.94 Safari/537.36',
'Referer': 'http://www.weiyun.com/disk/index-en.html'}
COOKIES = {'pgv_info': PGV_INFO,
'pgv_pvid': PGV_PVID,
'ptui_loginuin': EMAIL,
'pt2gguin': 'o'+UIN,
'uin': 'o'+UIN,
'skey': SKEY,
'ptisp': 'os',
'ptcz': PTCZ}
REQ_HEADER = {"cmd":"",
"main_v":11,
"proto_ver":10006,
"sub_v":1,
"encrypt":0,
"msg_seq":1,
"source":30234,
"appid":30234,
"client_ip":"127.0.0.1",
"token":TOKEN}
Now, we can start with setting up a base class on top of which we’ll implement all request types:
class BaseWeiyun(object):
def __init__(self, endpoint, cmd):
self.base = 'http://web.cgi.weiyun.com'
self.endpoint = endpoint
self.cmd = cmd
self.data = {"req_header":REQ_HEADER,
"req_body":{}}
self.data["req_header"]["cmd"] = cmd
def get_response(self):
url = self.base + self.endpoint
payload = self.get_payload()
r = requests.get(url, cookies=COOKIES, params=payload, headers=HEADERS)
response = r.text\
.replace('try{'+get_ordered_tuple(payload,"callback")+'(', '')\
.replace(')} catch(e){};', '')\
.replace(')}catch(e){};', '');
return json.loads(response)
def get_payload(self, isPost=False):
ruuid = str(uuid.uuid4()).upper().replace('-', '_')
prefix = 'post_callback' if isPost else 'get'
payload = (('cmd', self.cmd),
('g_tk', GTK),
('callback', prefix+'_'+ruuid),
('data', json.dumps(self.data)),
('_', str(current_milli_time())))
return payload;
The first request we’re going to implement is the “query user” command. After logging in the web app, this is the first request which will be executed to fetch some basic user info and stats:
class QueryUser(BaseWeiyun):
def __init__(self):
endpoint = '/wy_web_jsonp.fcg'
cmd = 'query_user'
super(QueryUser, self).__init__(endpoint, cmd)
Based on this, we’re ready to try out our class. Add the following snippet at the end:
req = QueryUser()
print jsonprint(req.get_response())
Executing this will yield something like the following if all goes well (if not, check whether you’ve set all constant values correctly):
{
"rsp_body": {
"IsFavoritesUser": 0,
"MaxBatchCopyFileCnt": "10",
"MaxBatchCopyFileToOffineCnt": "10",
"MaxBatchCopyFileToOtherbidCnt": "10",
"MaxBatchDeleteFileCnt": "50",
"MaxBatchDeleteFolderCnt": "10",
"MaxBatchDownloadFileCnt": "50",
"MaxBatchMoveFileCnt": "50",
"MaxBatchMoveFolderCnt": "10",
"MaxBatchRestoreFileCnt": "10",
"MaxBatchRestoreFolderCnt": "10",
"MaxFileAndFolderCnt": "200000",
"bat_del_limit": 0,
"bat_move_limit": 0,
"bat_sel_btn_flag": 0,
"bat_share_limit": 0,
"checksum": "1750865379",
"dir_count": 16,
"dir_level_max": 25,
"file_count": 938,
"filename_max_len": 128,
"filepath_max_len": 1024,
"get_timestamp_interval": 0,
"getlist_timestamp_flag": 1,
"is_new_user": 0,
"isset_passwd": 0,
"isset_pwd_qqdisk": 0,
"main_dir_key": "56e73eb0f0a739ae12b58dcd423dce4a",
"main_dir_name": "\u00e5\u00be\u00ae\u00e4\u00ba\u0091",
"main_key": "56e73eb0f0a739ae12b58dcd423dce4a",
"max_batch_dirs": 5,
"max_cur_dir_file": 954,
"max_dir_file": 65535,
"max_dl_tasks": 5,
"max_dts": 100000,
"max_fz": "2147483647",
"max_indexs_per_dir": 3000,
"max_interval_getlist": 1,
"max_note_len": 255,
"max_retry": 3,
"max_retry_interval": 0,
"max_single_file_size": "1048576",
"max_tasks": 10,
"max_thread_getlist": 3,
"max_ul_tasks": 10,
"mobile_accelerate_flag": false,
"nickname": "Seppe",
"pic_key": "56e73eb05984f9d6596c42937efab583",
"ps_move_count": 0,
"ps_move_flag": true,
"qdisk_psw": "",
"qqdisk_firstaccess_flag": 0,
"qqdisk_user_flag": 0,
"root_key": "56e73eb0f338fdcb41c5dfa52b9ed888",
"server_time": "1420220537307",
"show_whirlwind_space_flag": 0,
"stat_flag": false,
"stat_interval": 0,
"total_space": "12094627905536",
"used_space": "3443007169",
"user_authed": 1,
"user_ctime": "2014-04-05 20:49:30 319",
"user_mtime": "2015-01-02 21:17:17 067",
"user_type": 2,
"user_wright": 7,
"vip_level": 0,
"weixin_collect_flag": 0,
"weiyun_mobile": 0
},
"rsp_header": {
"cmd": "query_user",
"msg_seq": 1,
"ret": 0,
"uin": 2956912470
}
}
I love this example because it already shows how many limitations and extra flags there are in place. MaxFileAndFolderCnt, dir_level_max, filename_max_len, max_dir_file, vip_level? Interesting, and all a sign that it might not be easy to fill up this 20TB even if you’d try.
The next class implements the “root dir list” command:
class RootDirList(BaseWeiyun):
def __init__(self):
endpoint = '/weiyun_web_root_dir_list_cgi.fcg'
cmd = 'root_dir_list'
super(RootDirList, self).__init__(endpoint, cmd)
Test this out by the following snippet (remove the earlier one):
req = RootDirList()
print jsonprint(req.get_response())
This returns a list of folders and files in the root directory:
{
"rsp_body": {
"dirs": [
{
"dir_ctime": "2014-12-29 21:54:49 374",
"dir_key": "56e73eb054570c238a6a15604df9e583",
"dir_mtime": "2014-12-29 22:00:55 231",
"dir_name": "Music",
"dir_note": ""
}, [...]
],
"files": [
{
"file_ctime": "2015-01-02 20:30:03 000",
"file_cur_size": "148863",
"file_id": "d5574da1-7454-4669-93c1-745a040b482c",
"file_md5": "d7c2857279c7b77f1377d4a20e986b90",
"file_mtime": "2015-01-02 20:30:03 000",
"file_name": "Amazon2015-1-2 20.30.3.pdf",
"file_note": "",
"file_sha": "3970740694f57896fec1cb1a72dbed989b82f911",
"file_size": "148863",
"file_ver": "1420201803",
"source": ""
}, [...]
]
},
"rsp_header": {
"cmd": "root_dir_list",
"ret": 0
}
}
Interestingly, we see that folders are characterized by an MD5-looking key, whereas files have a UUID-looking identifier, as well as MD5 and SHA1 hashes.
The next command retrieves a similar listing, but for any directory:
class GetDirList(BaseWeiyun):
def __init__(self, dirkey, parentdirkey):
endpoint = '/wy_web_jsonp.fcg'
cmd = 'get_dir_list'
super(GetDirList, self).__init__(endpoint, cmd)
self.data["req_body"] = {
"pdir_key":parentdirkey,
"dir_key":dirkey,
"dir_mtime":"2000-01-01 01:01:01",
"only_dir":0}
Note that this command does not only require the folder key you wish to retrieve the listing for, but also its parent. Another strange aspect is the fact that we need to provide a dir_mtime parameter (perhaps it was planned to use this as an extra time based filter?). Let’s try this out with the “Music” directory as given above with key 56e73eb054570c238a6a15604df9e583. To retrieve the key of the parent directory (the root directory, in this case), we can look at the output of the “query user” command, which shows some promising candidates:
"root_key": "56e73eb0f338fdcb41c5dfa52b9ed888",
"main_dir_key": "56e73eb0f0a739ae12b58dcd423dce4a",
"main_dir_name": "\u00e5\u00be\u00ae\u00e4\u00ba\u0091",
"main_key": "56e73eb0f0a739ae12b58dcd423dce4a",
I’ll spoil the answer and tell right away that the main_dir_key is the one we need:
req = GetDirList(
'56e73eb054570c238a6a15604df9e583',
'56e73eb0f0a739ae12b58dcd423dce4a')
print jsonprint(req.get_response())
Gives:
{
"rsp_body": {
"dir_mtime": "2014-12-29 22:00:55 231",
"dirs": [
{
"dir_attr": {
"dir_name": "(A) in Mono"
},
"dir_attr_bit": "0",
"dir_ctime": "2014-12-29 22:00:33 527",
"dir_is_shared": 0,
"dir_key": "56e73eb067d21cb7c7ea0eec0bc21aa1",
"dir_mtime": "2014-12-31 23:41:22 663"
}
],
"files": null
},
"rsp_header": {
"cmd": "get_dir_list",
"msg_seq": 1,
"ret": 0,
"uin": 2956912470
}
}
You might think that this explains the reason why there exists separate commands for listing the main directory (as this one has no parent, right?) and other directories. Confusingly, this is not the case. Your main dir’s parent has another parent: the root directory given by:
"root_key": "56e73eb0f338fdcb41c5dfa52b9ed888",
You can test this out with:
req = GetDirList('56e73eb0f0a739ae12b58dcd423dce4a',
'56e73eb0f338fdcb41c5dfa52b9ed888')
print jsonprint(req.get_response())
Which works. Fun tip: you might have noticed that there is a pattern occurring for the folder keys. At this point, you might be wondering if this special root directory is a global one (with all users’ main directories under this one) and whether it is possible to access other user’s contents (i.e. whether the server-side checks your credentials). I tested this by setting up a second QQ account, and no, this attack does not work.
Next, we’ll implement a class to create directories:
class DirCreate(BaseWeiyun):
def __init__(self, dirname, parentdirkey, parentparentdirkey):
endpoint = '/wy_web_jsonp.fcg'
cmd = 'dir_create'
super(DirCreate, self).__init__(endpoint, cmd)
self.data["req_body"] = {
"ppdir_key": parentparentdirkey,
"pdir_key": parentdirkey,
"dir_attr": {"dir_name":dirname, "dir_note":""}}
def get_response(self):
url = self.base + self.endpoint
payload = self.get_payload(True)
r = requests.post(url, cookies=COOKIES, params=payload, data=payload, headers=HEADERS)
response = r.text\
.replace('<script>document.domain="weiyun.com";'+\
'try{parent.'+get_ordered_tuple(payload,"callback")+'(', '')\
.replace(')} catch(e){};</script>', '');
return json.loads(response)
Note that this class executes a POST request. The JSONP responses look a bit different, which is why we extend the get_response function.
Next up, classes to remove files and folders, which work in a similar manner but accept a list of names and keys:
class BatchFolderDelete(BaseWeiyun):
def __init__(self, dirnames, dirkeys, parentdirkeys, parentparentdirkeys):
endpoint = '/wy_web_jsonp.fcg'
cmd = 'batch_folder_delete'
super(BatchFolderDelete, self).__init__(endpoint, cmd)
dellist = []
for i in range(0, len(dirnames)):
dellist.append({"ppdir_key":parentparentdirkeys[i],
"pdir_key":parentdirkeys[i],
"dir_key":dirkeys[i],
"flag":1,
"dir_name":dirnames[i]})
self.data["req_body"] = {"del_folders": dellist}
def get_response(self):
url = self.base + self.endpoint
payload = self.get_payload(True)
r = requests.post(url, cookies=COOKIES, params=payload, data=payload, headers=HEADERS)
response = r.text\
.replace('<script>document.domain="weiyun.com";'+\
'try{parent.'+get_ordered_tuple(payload,"callback")+'(', '')\
.replace(')} catch(e){};</script>', '');
return json.loads(response)
class BatchFileDelete(BaseWeiyun):
def __init__(self, fileids, filenames, filevers, parentdirkeys, parentparentdirkeys):
endpoint = '/wy_web_jsonp.fcg'
cmd = 'batch_file_delete'
super(BatchFileDelete, self).__init__(endpoint, cmd)
dellist = []
for i in range(0, len(fileids)):
dellist.append({"ppdir_key":parentparentdirkeys[i],
"pdir_key":parentdirkeys[i],
"file_id":fileids[i],
"file_name":filenames[i],
"file_ver":filevers[i]})
self.data["req_body"] = {"del_files": dellist}
def get_response(self):
url = self.base + self.endpoint
payload = self.get_payload(True)
r = requests.post(url, cookies=COOKIES, params=payload, data=payload, headers=HEADERS)
response = r.text\
.replace('<script>document.domain="weiyun.com";'+\
'try{parent.'+get_ordered_tuple(payload,"callback")+'(', '')\
.replace(')} catch(e){};</script>', '');
return json.loads(response)
Next up is a big class in order to download files:
class DownloadFile(BaseWeiyun):
def __init__(self, fileid, filename, parentdirkey, checksum):
endpoint = '/wy_down.fcg'
cmd = None
super(DownloadFile, self).__init__(endpoint, cmd)
self.base = 'http://download.cgi.weiyun.com'
self.data = None
self.fileid = fileid
self.filename = filename
self.parentdirkey = parentdirkey
self.checksum = checksum
def get_response(self, stream=True):
url = self.base + self.endpoint
payload = self.get_payload()
headers = HEADERS.copy()
headers['origin'] = 'http://www.weiyun.com'
r = requests.post(url, cookies=COOKIES, params=payload, headers=headers, stream=stream)
return r
def callback(self, ds, sofar, total):
w = 80
sys.stdout.write( "\b" * (w+10) )
speed = ds / ((current_milli_time() - self.tb)/1000)
sys.stdout.write( "[%s%s] %s" %
("#" * (int(w * float(sofar) / float(total))),
" " * (w-(int(w * float(sofar) / float(total)))),
speed) )
def get_file(self, filename, stream=True, callback=None):
if callback is None:
callback = self.callback
a = self.get_response()
self.tb = current_milli_time()-1000
if stream:
total = 0
with open(filename, 'wb') as fd:
ds = 1024*100
for chunk in a.iter_content(ds):
total += len(chunk)
fd.write(chunk)
callback(ds, total, str(a.headers['content-length']))
print
a.close()
else:
with open(filename, 'wb') as fd:
fd.write(a.content)
fd.close()
def get_payload(self):
payload = (('fid', self.fileid),
('pdir', self.parentdirkey),
('fn', self.filename),
('uuin', UIN),
('skey', SKEY),
('appid', REQ_HEADER["appid"]),
('token', TOKEN),
('checksum', self.checksum),
('err_callback', 'http://www.weiyun.com/web/callback/iframe_disk_down_fail.html'),
('ver', REQ_HEADER["main_v"]))
return payload
Note that this endpoint requires crafting a payload which looks different than before. If the request succeeds, the server will respond with a 302 (Moved Temporarily) status code which requests will follow through to start downloading the file.
We can test it out as follows:
req = DownloadFile("0c72132f-4718-4da9-b735-bf17ce524a30",
"Amazon.pdf",
"56e73eb0f0a739ae12b58dcd423dce4a",
"1750865379")
req.get_file('c:/users/n11093/desktop/download.pdf')
Uploading files also requires some custom code:
class FileUpload(BaseWeiyun):
def __init__(self, filename, filesize, parentdirkey, parentparentdirkey, md5="", sha=""):
endpoint = '/upload.fcg'
cmd = 'file_upload'
super(FileUpload, self).__init__(endpoint, cmd)
utype = 1 if md5 == "" else 0
self.data["req_body"] = {"ppdir_key":parentparentdirkey,
"pdir_key":parentdirkey,
"upload_type": utype,
"file_md5":md5,
"file_sha":sha,
"file_size":str(filesize),
"file_attr":{"file_name":filename}}
self.parentdirkey = parentdirkey
self.parentparentdirkey = parentparentdirkey
def send_file(self, filename):
a = self.get_response()
print a
if (a['rsp_body']['file_exist']):
return True
elif self.data["req_body"]["upload_type"] == 0:
# Delete the broken file first, this is a side effect of trying with hashes first
o = BatchFileDelete(
[a['rsp_body']['file_id']],
[self.data["req_body"]["file_attr"]["file_name"]],
[a['rsp_body']['file_ver']],
[self.parentdirkey],
[self.parentparentdirkey])
oo = o.get_response()
req = FileUpload(self.data["req_body"]["file_attr"]["file_name"],
self.data["req_body"]["file_size"],
self.parentdirkey,
self.parentparentdirkey)
return req.send_file(filename)
elif self.data["req_body"]["upload_type"] == 1:
url = 'http://' + a['rsp_body']['upload_svr_host']+':'+\
str(a['rsp_body']['upload_svr_port']) + '/ftn_handler/'+\
'?ver=12345&ukey='+a['rsp_body']['upload_csum']+\
'&filekey='+a['rsp_body']['file_key']+'&'
headers = HEADERS.copy()
headers['origin'] = 'http://www.weiyun.com'
data = {'Filename': self.data["req_body"]["file_attr"]["file_name"],
'mode': 'flashupload',
'file': ('filename', open(filename, 'rb'), 'application/octet-stream'),
'Upload': 'Submit Query'}
r = requests.post(url, headers=headers, files={'file':data['file']})
return r
This class is interesting because we are making two requests here. First, we send of a request with an optionally given MD5 and SHA1 hash. If hashes are provided, the server can respond that the file exists and we can stop there. Even if the current user does not yet have the file in question, the hash matching is performed for every file on the system. If the file is not found (or not hashes are provided), the server will provide a location to which we can upload the file by a following POST (strangely enough, uploading with requests streaming behavior does not seem to work right, as the server closes the connection prematurely).
Note that we need to resend our request in case we try with hashes first and the file was not found. The new request will have no hashes and the upload type set to 1 (we do so by deleting the temporary broken file and calling a new FileUpload instance without hashes). The reasons for this is because the hashing functionality is provided by the browser plugin; when the file does not yet exist, the browser plugin will handle the uploading, which we cannot emulate here, therefore, we recreate the request to look like a normal, pure-browser one after which we can proceed to upload the file… This has some limitations in terms of maximum allowed size, however.
Trying this with an Ubuntu ISO file:
file = 'C:/users/n11093/Downloads/ubuntu-14.04.1-desktop-amd64.iso'
filename = 'ubuntu-14.04.1-desktop-amd64.iso'
hmd5 = md5(file)
hsha1 = sha1(file)
filesize = file_size(file)
req = FileUpload(
filename, filesize,
'56e73eb0f0a739ae12b58dcd423dce4a', '56e73eb0f338fdcb41c5dfa52b9ed888',
hmd5, hsha1)
print req.send_file('c:/users/n11093/desktop/download.pdf')
Yields True, i.e. the file existed already and was added to your drive. This makes for a very fun way to instantly share files, pirated movies, etc. with others…
Trying this with a non-existent file (and/or without providing hashes):
file = 'C:/users/n11093/Desktop/unique.txt'
filename = 'unique.txt'
filesize = file_size(file)
req = FileUpload(
filename, filesize,
'56e73eb0f0a739ae12b58dcd423dce4a', '56e73eb0f338fdcb41c5dfa52b9ed888')
print req.send_file('c:/users/n11093/desktop/download.pdf')
Will provide a 200 status code. Note that this’ll only work for smaller files. Uploading with larger files seems to perform multiple POSTs (the Windows client does so as well), which apply a custom-made encryption scheme which I did not reverse engineer — but continue to read on below…
Tokens
If you recall the following lines:
TOKEN = 'changeme'
GTK = 'changeme'
You might recall that these are sent with every request, and do not change during the lifetime of the session. Since requests are made client-side (i.e. initiated by Javascript), we could try to see if we can derive where they are coming from.
We can easily conjure up the call trace from Chrome when making a request:

This indicates that our point of interest might be in common.index.js or in main.index.js. Indeed, in the former, we find a line:
token:security.getAntiCSRFToken()
Which refers to:
security=lib.get('./security'),
Which we then find in lib.index.js:
function _getAntiCSRFToken(objConfig){
objConfig=objConfig||{};
var salt=objConfig.salt||CONST_SALT;
var skey=objConfig.skey||cookie.get("skey");
var md5key=objConfig.md5key||CONST_MD5_KEY;
var hash=[],ASCIICode;
hash.push((salt<<5));
for(var i=0,len=skey.length;i<len;++i){
ASCIICode=skey.charAt(i).charCodeAt();
hash.push((salt<<5)+ASCIICode);
salt=ASCIICode;
}
var md5str=_md5(hash.join('')+md5key);
return md5str;
}
We can find a similar function for the g_tk parameter. Re-implementing these in Python is easy:
def get_token(skey, md5key='tencentQQVIP123443safde&!%^%1282', salt=5381):
thash = []
num = salt<<5
thash.append(str(num))
for i in range(0, len(skey)):
ac = ord(skey[i])
num = (salt<<5)+ac
thash.append(str(num))
salt = ac
return hashlib.md5(''.join(thash)+md5key).hexdigest()
def get_tk(skey, salt=5381):
for i in range(0, len(skey)):
ac = ord(skey[i])
salt += (salt<<5)+ac
return salt&0x7fffffff;
And change:
TOKEN = get_token(SKEY)
GTK = get_tk(SKEY)
Again, a lovely display of custom-rolled security functions. I wonder how developer team meetings at Tencent would go.
Download
I’ve put all my code up on GitHub, in case you’re interested. I’ll probably not maintain this for long, but feel free to fork or submit pull requests. The license is permissive (MIT), and I’d love to hear if this ends up being useful in some way. I can be reached at macuyiko@gmail.com (我也明白一点ä¸æ–‡).
Addendum: Tencent’s Encrypted Chunked Upload Mechanism
At the time of writing up this post (which took a few days), I noticed that the upload mechanism over at the English version of Weiyuns app became increasingly flaky. At first, I thought this was an issue with my code, but uploading through the site itself also seems to be failing (at least at this moment in time).
I took a look at the Chinese version to see if things were still working there, and it seems that indeed, it does. In addition, I’ve noticed that this version now relies on a Flash helper which performs uploads in the same manner as the Window client does (verified using Wireshark). First, a request is made to an API endpoint (http://user.weiyun.com/newcgi/qdisk_upload.fcg) to get a location to upload to (similar as before). Next however, a series of POST requests is made which seem to upload chunks of the file to be uploaded with some magic header stuck in the front.
To figure out how this works, we decompile http://img.weiyun.com/club/qqdisk/web/FileUploader.swf and have a look. In there, we find the function we’re looking for:
public function byteupload(data:String, offset:int):void{
var ctx:MD5Context = new MD5Context();
MD5Inc.update(ctx, Base64.decode(data));
var _md5:String = MD5Inc.result(ctx);
var up_url:String = (((((((this.protocol + this.server) + ":") + this.port) + "/ftn_handler/") + this.md5) + "?bmd5=") + _md5);
var ur:URLRequest = new URLRequest(up_url);
ur.method = URLRequestMethod.POST;
ur.contentType = "application/octet-stream";
ur.data = new FTNUploadFileProtocol().getFTN_Bytes(this, data, offset);
this.uper = new URLLoader();
this.uper.addEventListener(Event.COMPLETE, this._completeHandler);
this.uper.addEventListener(IOErrorEvent.IO_ERROR, this._errorHandler);
this.uper.addEventListener(ProgressEvent.PROGRESS, this._progressHandler);
this.uper.addEventListener(SecurityErrorEvent.SECURITY_ERROR, this._securityerrorHandler);
this.uper.addEventListener(HTTPStatusEvent.HTTP_STATUS, this._httpStatusHandler);
this.uper.dataFormat = URLLoaderDataFormat.BINARY;
this.uper.load(ur);
}
getFTN_Bytes defines the composition of each chunk:
public function getFTN_Bytes(file:FileByteArray, data:String, offset:int):ByteArray{
var bytes:ByteArray = new ByteArray();
bytes.writeInt(2882377846);
bytes.writeInt(1000);
bytes.writeInt(0);
var tempUkey:ByteArray = this.Str2Bin(file.uKey);
var tempFileKey:ByteArray = this.Str2Bin(file.fileKey);
var tempData:ByteArray = Base64.decodeToByteArray(data);
var len:int = (((((2 * 2) + (4 * 3)) + tempUkey.length) + tempFileKey.length) + tempData.length);
bytes.writeInt(len);
bytes.writeShort(tempUkey.length);
bytes.writeBytes(tempUkey);
bytes.writeShort(tempFileKey.length);
bytes.writeBytes(tempFileKey);
bytes.writeInt(file.size);
bytes.writeInt(offset);
bytes.writeInt(tempData.length);
bytes.writeBytes(tempData);
return (bytes);
}
Based on this, we can start implementing this in Python:
class ChunkedFileUpload(BaseWeiyun):
def __init__(self, filename, filesize, parentdirkey, parentparentdirkey, fmd5, fsha):
utype = 1 if fmd5 == "" else 0
self.base = 'http://user.weiyun.com/newcgi'
self.endpoint = '/qdisk_upload.fcg'
self.cmd = '2301'
self.data = {"req_header":{
"cmd":int(self.cmd),
"appid":30013,
"version":2,
"major_version":2},
"req_body":{
"ReqMsg_body":{
"weiyun.DiskFileUploadMsgReq_body":{
"ppdir_key":parentparentdirkey,
"pdir_key":parentdirkey,
"upload_type":utype,
"file_md5":fmd5,
"file_sha":fsha,
"file_size":filesize,
"filename":filename,
"file_exist_option":4}}}}
self.parentdirkey = parentdirkey
self.parentparentdirkey = parentparentdirkey
def get_response(self):
url = self.base + self.endpoint
payload = self.get_payload()
headers = HEADERS.copy()
headers['Referer'] = 'http://user.weiyun.com/cdr_proxy.html'
r = requests.get(url, cookies=COOKIES, params=payload, headers=headers)
response = r.text\
.replace('try{X_GET(', '')\
.replace(')}catch(e){};', '');
return json.loads(response)
def get_payload(self):
payload = (('cmd', self.cmd),
('g_tk', GTK),
('data', json.dumps(self.data)),
('callback', 'X_GET'),
('_', str(current_milli_time())))
return payload;
def callback(self, send, total):
print send, total
def send_file(self, filename, callback=None):
if callback is None:
callback = self.callback
a = self.get_response()
rspbody = a['rsp_body']['RspMsg_body']['weiyun.DiskFileUploadMsgRsp_body']
print rspbody
if rspbody['file_exist'] and False:
return True
else:
print ''
url = 'http://' + rspbody['server_name']+':'+\
str(rspbody['server_port']) + '/ftn_handler/'+\
self.data['req_body']['ReqMsg_body']['weiyun.DiskFileUploadMsgReq_body']['file_md5']
headers = HEADERS.copy()
headers['origin'] = 'http://img.weiyun.com'
length = 131072
filekey = rspbody['file_key']
ukey = rspbody['check_key']
for start in range(0, file_size(filename), 131072):
chunk = get_chunk(filename, start, length)
encch = encode_chunk(ukey, filekey, filename, start, chunk)
bmd5 = '?' # TODO: requires conversion of crypto
print bmd5
r = requests.post(url+ '?bmd5=' + bmd5, headers=headers, data = encch)
if callback is not None:
callback(start + length, file_size(filename))
The line of interest here is:
bmd5 = '?' # TODO: requires conversion of crypto
Corresponding with the following lines in the Flash source:
var ctx:MD5Context = new MD5Context();
MD5Inc.update(ctx, Base64.decode(data));
var _md5:String = MD5Inc.result(ctx);
Sadly, the underlying classes (MD5Context and friends) in the decompiled Flash source correspond with a custom-made crypto library which is thousands of lines long. I don’t feel very inclined to convert these all at the moment, and SWF<->Anything interaction is a pipe dream (for “Anything” being anything else than Javascript, that is). The code of interest is on GitHub, so feel free to take a stab at it if willing. Note that doing so will eventually allow uploading files of arbitrary size.
Extra Fun: Getting User Profile Pictures
Whilst browsing to the request made by Chrome, I noticed a particular one to http://ptlogin2.weiyun.com/getface. This endpoint allows to get a user profile picture for any QQ number, without having to be logged in. This is not a security breach in itself (since these pictures are meant to be public avatars), but still fun to automate nonetheless, especially since pictures can be quite large in size:
import requests
import json
import os
import sys
from multiprocessing import Pool
from multiprocessing.dummy import Pool as ThreadPool
def get_face(uid, itype=5):
payload = (
('appid', str(527020901)),
('imgtype', str(itype)),
('encrytype', '0'),
('devtype', '0'),
('keytpye', '0'),
('uin', str(uid)))
r = requests.get(url='http://ptlogin2.weiyun.com/getface', params=payload)
response = r.text\
.replace('pt.setHeader(', '')\
.replace(');', '');
return json.loads(response)
def parse(i):
url = get_face(i)[str(i)]
if '&t=0' in url: return
r = requests.get(url=url)
if r.status_code == 200:
with open('./images/'+str(i)+'.jpeg', 'wb') as f:
f.write(r.content)
print str(i),url
pool = ThreadPool(4)
start = 2756800000
length = 10000
uids = range(start, start+length)
results = pool.map(parse, uids)
pool.close()
pool.join()
I’d love to see a project combining computer vision with this and do some unsupervised clustering ;).
Notes
[1]: See for instance http://www.reuters.com/article/2014/12/29/google-china-idUSL3N0UD21W20141229 for a very recent example. Although to be clear, plain old censorship is the main driver behind such moves. Still, there is a bit of protectionism mixed in which can go quite far. A typical strategy applied for example is to allow access to Google Maps or Gmail for very brief periods, in order to instill the notion that Google is just offering sloppy services. Most netizens are smart enough not to fall for it, however.
[2]: I’ve noticed this myself when trying to find standard notation for terms which are generally accepted in English research literature, such as “recall and precision”. The New York times also has two great articles here (older) and here on the subject (the latter article is a great read and better expands on some points I’m making here). To quote:
“I know some foreign scientists are studying the rings of ancient trees to learn about the climate, for example, but I can’t find their work using Baidu,” Ms. Jin said. “When in China, I’m almost never able to access Google Scholar, so I’m left badly informed of the latest findings.”
[3]: I really like the hanzi 盘 to indicate a disk. The character is a pretty old-fashioned one to indicate a dish, plate, or even a washbasin. It is used in 硬盘 to indicate hard drive.