Update: code is available at https://github.com/Macuyiko/gmail-cleaner.
I’ve been getting increasingly frustrated by my overflowing Gmail inbox lately. I’ve been using Gmail as a primary e-mail service since 2005 and have collected tens of thousands emails over the years.
Lately, I’ve been finding it increasingly harder to quickly find an e-mail using Gmails otherwise solid search functionality. The problem is mostly due to me not using much labels on the one hand and archiving, rather than deleting junky e-mails on the other hand. The latter stems from Gmail’s “training”, inspiring users to archive e-mails rather than deleting them, since storage is never really an issue.
Indeed, it never is, but over the years, several parties collect your e-mail address to send you weekly digests, newsletters, “what’s new” overviews, and updates regarding your social networks you never really bother to visit anymore (LinkedIn, Facebook, Twitter, ResearchGate are all annoying offenders). It’s appealing to just straight up archive these, but since there’s always some overlap in content between what you’re actually trying to search for and what ends up in those e-mails (e.g. “data science collaboration project”), it can become annoying to quickly glance over e-mails and find what you’re looking for. Starring e-mails and filtering them further helps, of course, but I felt it was about time to do something about this pile of archived e-mails I’d never bother to look at again.
The issue, however, that “safely” cleaning up these e-mails is rather tricky. Just deleting all archived e-mails is out of the question… there might still be important or interesting mails there. Searching based on the “from” header and going from there is better, but Gmail forces to paginate over the list (showing hundred e-mails per page) and does not intelligently group e-mails to make ticking their checkboxes easy. To provide an example, I might wish to delete all those Amazon recommended products mails, but do not want to delete my latest shipping confirmations. Gmail’s interface can also feel sluggish at times when ticking of mails, deleting them, going back to the search field, ticking again, and so on. Finally, Gmail does not provide an easy way to show e-mails grouped by sender, to get an easy overview regarding the most frequent “spammers”.
Probably a solid desktop client (Outlook, even) provides better functionality to do this sort of thing, but I wanted to quicky punch together a Python driven app instead to help clean up my inbox.
First up was connecting with Gmail’s API to create a local database I could work with. You could use IMAP as well, though using Gmail’s incantation of IMAP is somewhat annoying, having to do the whole oauth2 dance, not really providing an easy way to access unique message ids, and trashing e-mails boils down to executing IMAP move commands. The API works much better.
from model import *
import httplib2
import os
from apiclient import discovery
from oauth2client import client
from oauth2client import tools
from oauth2client.file import Storage
from tqdm import tqdm
from joblib import Parallel, delayed
from collections import defaultdict
import multiprocessing
# We need to modify scope here to trash e-mails later on
SCOPES = 'https://www.googleapis.com/auth/gmail.modify'
CLIENT_SECRET_FILE = 'client_secret.json'
APPLICATION_NAME = 'Gmail API Python Quickstart'
DATABASE = EmailDB(db_path)
def ParallelExecutor(use_bar='tqdm', **joblib_args):
def aprun(bar=use_bar, **tq_args):
bar_func = lambda x: tqdm(x, **tq_args)
def tmp(op_iter):
return Parallel(**joblib_args)(bar_func(op_iter))
return tmp
return aprun
def get_credentials():
home_dir = os.path.expanduser('~')
credential_dir = os.path.join(home_dir, '.credentials')
if not os.path.exists(credential_dir):
os.makedirs(credential_dir)
credential_path = os.path.join(credential_dir, 'gmail-python-quickstart.json')
store = Storage(credential_path)
credentials = store.get()
if not credentials or credentials.invalid:
flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES)
flow.user_agent = APPLICATION_NAME
credentials = tools.run_flow(flow, store, None)
print('Storing credentials to ' + credential_path)
return credentials
def get_service():
credentials = get_credentials()
http = credentials.authorize(httplib2.Http())
service = discovery.build('gmail', 'v1', http=http)
return service
def fill_db():
service = get_service()
token = None
DATABASE.clear_emails()
while True:
results = service.users().messages().list(userId='me', pageToken=token).execute()
messages = results.get('messages', [])
DATABASE.insert_emails([(message['id'],) for message in messages])
token = results.get('nextPageToken')
if not token:
break
def fetch_headers(id):
service = get_service()
get_header = lambda x, name: [y for y in x if y.get('name') == name][0]['value']
result = service.users().messages().get(userId='me', id=id).execute()
try:
fromf = get_header(result['payload']['headers'], 'From')
subject = get_header(result['payload']['headers'], 'Subject')
return (id, fromf, subject)
except:
return (id, None, None)
def update_headers(chunks):
num_cores = 4
aprun = ParallelExecutor(n_jobs=num_cores)
results = aprun(bar='tqdm')(delayed(fetch_headers)(id) for id in chunks)
for id, fromf, subject in tqdm(results):
if subject is None or fromf is None:
DATABASE.trash_email(id)
else:
DATABASE.update_email(id, fromf, subject)
def update_db():
chunk_size = 300
chunks = []
for email in tqdm(DATABASE.select_updateable_emails()):
chunks.append(email['id'])
if len(chunks) >= chunk_size:
update_headers(chunks)
chunks = []
update_headers(chunks)
if __name__ == '__main__':
if not DATABASE.has_emails():
print('Database is empty, performing first-time setup')
fill_db()
print('Updating messages')
update_db()
I’m only fetching the unique id here, together with the from and subject headers. Quite annoyingly, even though the Gmail API provides batch calls to delete and modify a list of e-mails, it does not expose similar functionality to get a list of e-mails. Instead, service.users().messages().list(...) provides a paginated result list of e-mail ids and thread ids, without detailed information. Afterwards, you need to loop through all e-mail ids to service.users().messages().get(...) their details. I’m using joblib here to speed up this process:

A few hours later, the database is filled up and ready for use. A simple SQL statement can immediately provide a grouped overview of e-mails per sender:
SELECT header_from, count(*) AS "amount" FROM "email"
WHERE "trashed" = 0
GROUP BY "header_from"
ORDER BY "amount" DESC
Next up is making trying to group e-mails (for a particular sender) based on their subjects to make it easier to spot repeating e-mails. Doing so using a string identity based aggregation is easy, though the issue is that subjects will be slightly different over time for many senders, e.g. compary “your weekly digest for 11/2017” verus “your weekly digest for 12/2017” or “12 friends have liked your profile” versus “1 friend has liked your profile”.
It turns out that this problem is heavily related to the field of sequence alignment, a common task in bioinformatics were sequences are grouped based on regional similarity as well as visualized in such a manner that the similar fragments are easy to identify:

Several toolkits exist for sequence (or string) alignment. In Python, there’s swalign which implements a Smith-Waterman local aligner. BioPython also contains several ways for sequence alignment. There’s also alignment. There’s also MAFFT in case you want a fast non-Python implementation.
However, Python also comes with the difflib module, which implements Ratcliff and Obershelp’s “gestalt pattern matching” algorithm, used to provide diff’s between two inputs. It basically boils down to finding the smallest set of deletions and insertions to create one input from the other. Normally, diff tools work line-oriented, though difflib’s SequenceMatcher class can also work character-oriented:
>>> a = "You have a message from Name Lastname waiting for 3 days"
>>> b = "You have a message from Jon Snow waiting for 393 days"
>>> s = SequenceMatcher()
>>> s.set_seq1(a)
>>> s.set_seq2(b)
>>> s.ratio()
0.8256880733944955
>>> s.get_matching_blocks()
[Match(a=0, b=0, size=24), Match(a=28, b=27, size=1), Match(a=33, b=29, size=1), Match(a=37, b=32, size=14), Match(a=51, b=48, size=5), Match(a=56, b=53, size=0)]
This provides us with a “good enough” mechanism to find a distance (ratio) between to strings, as well as their matching pieces. The challenge is now to use this building block to group a list of subjects together.
Whenever you’re faced with a clustering task such as this, and you have a method to establish a “distance” between to elements, it turns out to be easy to turn this into a complete clustering solution. One way to do so is by implementing Agglomerative Hierarchical Clustering. This algorithm works in a series of steps where in every step a new level in the “hierarchy” is constructed.
- At the “first, lowest” level, every element forms a cluster on its own
- Find two clusters A and B with the best linkage criterion
- Merge these two together and add to the next level
- All other clusters remain as is and are added to the next level
- Repeat until every element is in one single cluster (or until the best linkage value drops below a threshold and you’ve reached the desired number of clusters)
For the first iteration, finding the best linkage criterion is easy. We can just use the .ratio() method from SequenceMatcher between two clusters A and B since they both contain one sequence each. How do we apply the same mechanism once clusters start to contain more than one sequence?
A first approach was to use a centroid based criterion. This requires us to define a “centroid” between sequences with their distance then simply being the distance between the centroids. In this case, we can just use a very naive approach where .get_matching_blocks() is used to keep the similar pieces of two strings, and replace the non matching parts with a replacement character, like so:
def combine_strings(blocks, a, b, char='-', min_thres=3):
combined = ''
last_a, last_b = 0, 0
for block in blocks:
# Add maximum suffix
combined += char * max(block.a - last_a, block.b - last_b)
last_a = block.a + block.size
last_b = block.b + block.size
piece_to_add = a[block.a:block.a+block.size] # Guaranteed to be == b[j:j+n]
combined += piece_to_add if len(piece_to_add) > min_thres else char * len(piece_to_add)
combined += char * (len(combined) - max(len(a), len(b)))
return combined
>>> combine_strings(s.get_matching_blocks(), a, b)
You have a message from ------------- waiting for 3-- days--
The latter is a good aggregated representation of our two subjects and can be easily represented to the user.
The full Agglomerative Hierarchical Clustering setup then looks like this:
def find_best_match(clusters, ratio_threshold):
s = SequenceMatcher()
best_abval = (None, None, 0, None)
# Find best match using centroid method
for i in range(len(clusters) - 1):
for j in range(i + 1, len(clusters)):
s.set_seq1(clusters[i].centroid)
s.set_seq2(clusters[j].centroid)
r = s.ratio()
if r > best_abval[2] and r >= ratio_threshold:
best_abval = (i, j, r, s.get_matching_blocks())
return best_abval
def cluster_strings(strings, ratio_threshold=0.6, combiner=combine_strings, matcher=find_best_match):
Cluster = namedtuple('Cluster', 'centroid members parents')
dendrogram = [
# First level of clusters:
[Cluster(centroid=x, members=[x], parents=None) for x in strings]
]
while len(dendrogram[-1]) > 1:
best_abval = matcher(dendrogram[-1], ratio_threshold)
if best_abval[3] is None:
# Threshold could not be adhered to, stop clustering here
break
new_level = []
for i in range(len(dendrogram[-1])):
if i == best_abval[0] or i == best_abval[1]:
continue
m = dendrogram[-1][i]
new_level.append(Cluster(centroid=m.centroid, members=m.members, parents=(i,)))
first_centroid = dendrogram[-1][best_abval[0]].centroid
second_centroid = dendrogram[-1][best_abval[1]].centroid
merged_centroid = combiner(best_abval[3], first_centroid, second_centroid)
new_level.append(Cluster(centroid=merged_centroid,
members=dendrogram[-1][best_abval[0]].members + dendrogram[-1][best_abval[1]].members,
parents=(best_abval[0], best_abval[1])))
dendrogram.append(new_level)
return dendrogram
And then:
>>> strings = ["You have a message from Name Lastname waiting for 3 days",
"You have a message from Jon Snow waiting for 393 days",
"You have a message from Bob Bobbert waiting for 4 days",
"You have a message from Marc Marcussen waiting for 1 day",
"Jon Snow liked a photo of you",
"Laurence Marcus liked a photo of you",
"Aurelie liked a photo of you",
"Jon Snow is waiting for your reply"]
>>> cluster_tree = cluster_strings(strings)
>>> for cluster in cluster_tree[-1]: print(cluster.centroid)
Jon Snow is waiting for your reply
You have a message from ---------------------- waiting for --- day--------------
--------------- liked a photo of you
Looks good. One issue is, however, that SequenceMatcher is quite slow. The two nested for loops in cluster_strings also don’t help here. What if we could calculate the ratios between all pairs of subjects just once, and go from there? I.e. we’re going to change the linkage criterion to a single (or minumum) one, so that the distance between clusters A and B is now min(d(a,b) where a is in A and b is in B).
We’ll also refactor the code to do away with keeping track of the different levels in the hierarchy, since we only want the final outcome anyway:
from difflib import SequenceMatcher
from functools import lru_cache
def combine_strings(a, b, char='-', min_thres=3):
s = SequenceMatcher()
s.set_seq1(a)
s.set_seq2(b)
blocks = s.get_matching_blocks()
combined = ''
last_a, last_b = 0, 0
for block in blocks:
combined += char * max(block.a - last_a, block.b - last_b)
last_a = block.a + block.size
last_b = block.b + block.size
piece_to_add = a[block.a:block.a+block.size]
combined += piece_to_add if len(piece_to_add) > min_thres else char * len(piece_to_add)
combined += char * (len(combined) - max(len(a), len(b)))
return combined
def combine_clusters(clusters):
representations = []
for cluster in clusters:
representation = cluster
while len(representation) > 1:
a = representation.pop()
b = representation.pop()
representation.append(combine_strings(a, b))
representations.append(representation[0])
return representations
@lru_cache(maxsize=1024)
def get_ratio(a, b):
s = SequenceMatcher()
s.set_seq1(a)
s.set_seq2(b)
return s.ratio()
def find_best_match(clusters, ratio_threshold):
s = SequenceMatcher()
best_abval = (None, None, 0)
for i in range(len(clusters) - 1):
for j in range(i + 1, len(clusters)):
r = min([get_ratio(a, b) for a in clusters[i] for b in clusters[j]])
if r > best_abval[2] and r >= ratio_threshold:
best_abval = (i, j, r)
return best_abval
def cluster_strings(strings, ratio_threshold=0.6, combiner=combine_clusters, matcher=find_best_match):
clusters = [[x] for x in strings]
while len(clusters) > 1:
best_abval = matcher(clusters, ratio_threshold)
if best_abval[0] is None:
break
new_level = []
for i in range(len(clusters)):
if i == best_abval[0] or i == best_abval[1]:
continue
new_level.append(clusters[i])
new_level.append(clusters[best_abval[0]] + clusters[best_abval[1]])
clusters = new_level
return combiner(clusters), clusters
Note that we still combine the clusters together to get a final representation. We’re also using lru_cache here to solve the pairwise ratio computation issue without adding in additional code.
Now what remained is to hook this up to a simple Flask application. Note that trashing e-mails using Gmails API can be done in batch using:
service.users().messages().batchModify(userId='me', body={
'removeLabelIds': [],
'addLabelIds': ['TRASH'],
'ids': email_ids
}).execute()
This is how the result looks like:
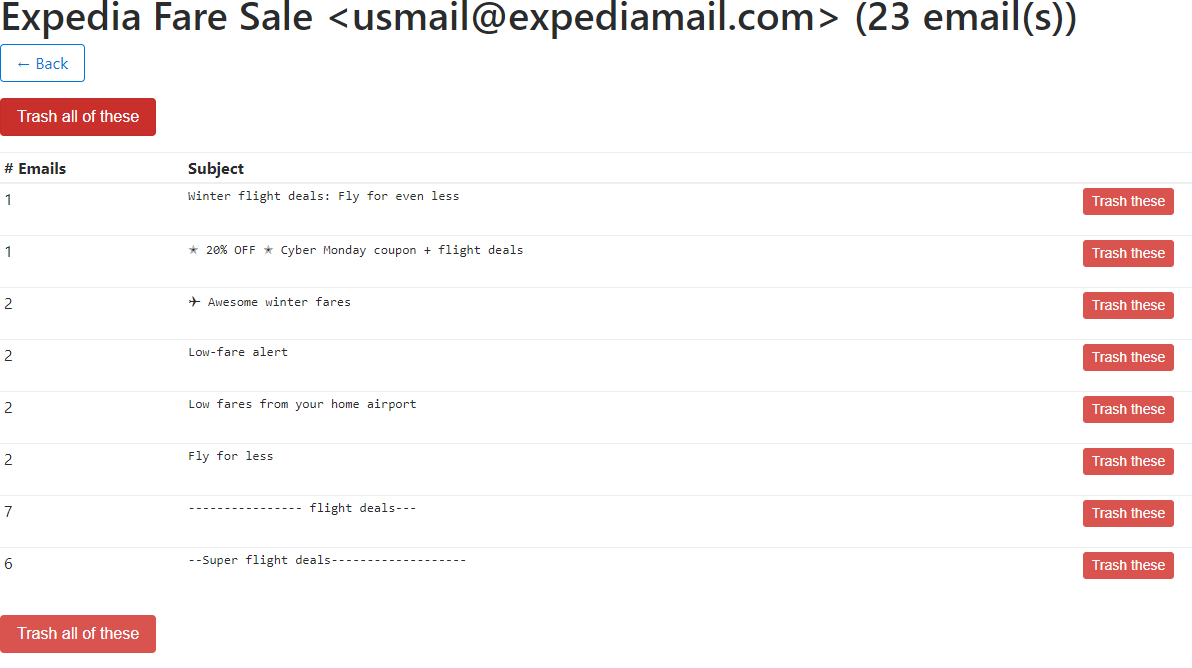
E-mails that are trashed will get a flag in the local database in order to prevent them showing up in the overall list.
Using this overview, I was able to delete about twenty thousand e-mails in half an hour or so.